胡家菘,公開資訊觀測站,基本資料,上市公司,簽證會計師,樞紐分析
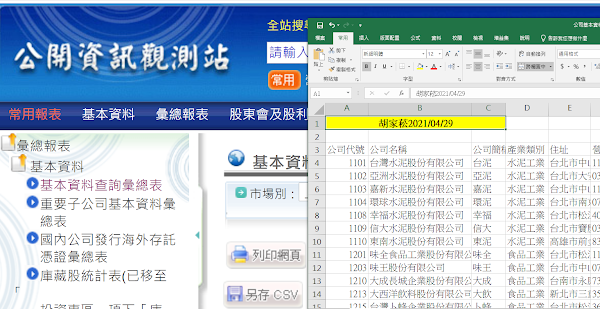
公開資訊觀測站,基本資料 樞紐分析:簽證會計師(列),樞紐分析(欄) 樞紐分析表Pivot Table 篩選Filters: 列Rows:會計師事務所 欄Columns: 產業類別 值Value:董事長(計數) 最大的五家事務所 上市客戶數 勤業眾信聯合會計師事務所 360 資誠聯合會計師事務所 206 安侯建業聯合會計師事務所 202 安永聯合會計師事務所 94 國富浩華聯合會計師事務所 27 公開資訊觀測站是模仿美國EDGAR 台灣的公開資訊觀測站隸屬於台灣正卷交易所股份有限公司,美國的EDGAR直接隸屬於聯邦政府的證卷交易委員會。 EDGAR(Electronic Data Gathering, Analysis, and Retrieval System) EDGAR即電子化數據收集、分析及檢索系統 。1996年,美國 SEC 規定所有的信息披露義務人(美國 上市公司 )都必須進行電子化入檔。為了確保我們可以追蹤您的使用情況,Vintage Filings會將所發生的全部書面郵件、傳真抄送給新華美通,以保證我們在全程中向您提供質量一流的服務。 劉任昌088教學影片 劉任昌089教學影片